
一、前言
1. 我为什么要做这个实验
到2011年寒假之末,我终于把当前java主流的三大开源框架——hibernate,struts,spring——初步学完。我看的是尚学堂马士兵老师的视频教程。学完后觉得必须找点东西练练手,于是自己意淫出一个小项目,计划用三大框架,结合软件工程的一些知识去把它做出来,以巩固刚学到一些用法。
但是,我在开始就遇到了难题——数据库如何设计、hibernate里的关联是啥回事、ER图如何设计?这时我才发现我其实根本就不懂数据库。记得我当时是如何开心而轻松的看完马士兵老师关于关联的教程,现在才知道我没有从稍微根本的层面去理解关联。这个实验就是为了帮助我“从稍微根本的层面去理解关联”而做的。
2. 希望带给读者啥
在这次比较认真的实验之前,我零零星星的做了好多次各种情况的实验,试图帮助自己更好的理解关联,但是我的意图都没达到。原因是我每次实验后都试图把结果记住而达到目的,但事实上结果我很快就忘记了,忘记了又得做。所以这次索性做认真点,做完之后也不去记实验结果,而是去总结关系数据库是如何表示实体之间的关联的。也希望大家不要记实验结果,而去理解规律。
实验中有错误之处,请无情指出,笔者会及时改过,以免误人子弟:)。
二、实验环境
1. 用到的工具
myeclipse集成环境,powerdesigner数据库工具,mysql数据库,mysql query browser图形化管理工具。
本实验只用到hibernate框架,所有数据库表都有hibernate自动生成。而且为了写文档的方便,用的是hibernate annotation做的实验。
工程环境见下图:

图表 1工程环境
1. 主要代码
第一个类:
package me.hibernate.model;import java.util.*;import javax.persistence.CascadeType;import javax.persistence.Entity;import javax.persistence.GeneratedValue;import javax.persistence.Id;import javax.persistence.JoinColumn;import javax.persistence.OneToMany;import javax.persistence.Table;@Entity@Table(name="myGroup")public class Group { private int id; private String name; private Set users = new HashSet (); @OneToMany(cascade={CascadeType.ALL}) @JoinColumn(name="groupId") public Set getUsers() { return users; } public void setUsers(Set users) { this.users = users; } @Id @GeneratedValue public int getId() { return id; } public String getName() { return name; } public void setId(int id) { this.id = id; } public void setName(String name) { this.name = name; }} 第二个类:
package me.hibernate.model;import javax.persistence.Entity;import javax.persistence.GeneratedValue;import javax.persistence.Id;import javax.persistence.ManyToOne;import javax.persistence.Table;@Entity@Table(name="myUser")public class User { private int id; private String name; private Group group; @Id @GeneratedValue public int getId() { return id; } public String getName() { return name; } public void setId(int id) { this.id = id; } public void setName(String name) { this.name = name; } public void setGroup(Group group) { this.group = group; } @ManyToOne() public Group getGroup() { return group; }} Junit测试类:
package me.hibernate.model;import java.util.*;import org.hibernate.Session;import org.hibernate.cfg.AnnotationConfiguration;import org.junit.Test;public class TestORM { @Test public void testSave(){ User u1,u2,u3; Group g; Set users = new HashSet (); u1 = new User(); u2 = new User(); u3 = new User(); g = new Group(); u1.setName("me"); u2.setName("you"); u3.setName("him"); users.add(u1); users.add(u2); users.add(u3); g.setName("bigGroup"); g.setUsers(users); AnnotationConfiguration cfg = new AnnotationConfiguration(); Session session = cfg.configure().buildSessionFactory().getCurrentSession(); session.beginTransaction(); session.save(g); session.getTransaction().commit(); }} hibernate配置文件:
com.mysql.jdbc.Driver jdbc:mysql://localhost:3306/hibernate root root org.hibernate.dialect.MySQLDialect thread org.hibernate.cache.NoCacheProvider true update true
三、实验内容
以下只贴出在实验中改变的代码。在实验的每一个步骤(以为8个步骤,而非2个步骤)之前,上一步骤中生成的数据库表会被全部删除,以免干扰当前的实验内容。其中每一步骤,junit方法都没有报错,最大程度的确保实验结果的可靠性。
1. 双向关联
1) 双向关联,有JoinColumn,无mappedBy
做出改动的代码 | |
Group类 | User类 |
@OneToMany(cascade={CascadeType.ALL}) @JoinColumn(name="groupId") public Set<User> getUsers() { return users; } | @ManyToOne() public Group getGroup() { return group; } |

图表 2 数据库内生成的表
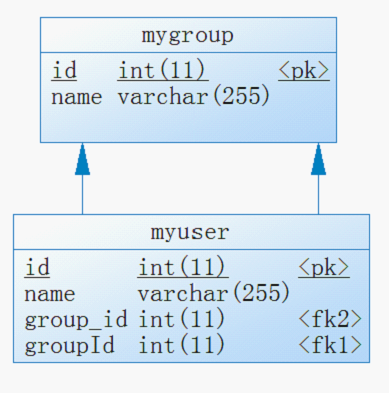
图表 3用powerdesigner对表进行逆向的结果
1) 双向关联,无JoinColumn,无mappedBy
做出改动的代码 | |
Group类 | User类 |
@OneToMany(cascade={CascadeType.ALL}) public Set<User> getUsers() { return users; } | @ManyToOne() public Group getGroup() { return group; } |

图表 4 数据库内生成的表

图表 5 用powerdesigner对表进行逆向的结果
1) 双向关联,有JoinColumn,有mappedBy
做出改动的代码 | |
Group类 | User类 |
@OneToMany(mappedBy="group",cascade={CascadeType.ALL}) @JoinColumn(name="groupId") public Set<User> getUsers() { return users; } | @ManyToOne() public Group getGroup() { return group; } |
图表 6 数据库内生成的表

图表 7 用powerdesigner对表进行逆向的结果
1) 双向关联,无JoinColumn,有mappedBy
做出改动的代码 | |
Group类 | User类 |
@OneToMany(mappedBy="group",cascade={CascadeType.ALL}) public Set<User> getUsers() { return users; } | @ManyToOne() public Group getGroup() { return group; } |

图表 8 数据库内生成的表

图表 9 用powerdesigner对表进行逆向的结果
1. 单向关联
1) 无JoinColumn,User类无group属性
做出改动的代码 | |
Group类 | User类 |
@OneToMany(cascade={CascadeType.ALL}) public Set<User> getUsers() { return users; } | 无group属性 |

图表 10 数据库内生成的表

图表 11 用powerdesigner对表进行逆向的结果
1) 有JoinColumn,User类无group属性
做出改动的代码 | |
Group类 | User类 |
@OneToMany(cascade={CascadeType.ALL}) @JoinColumn(name="groupId") public Set<User> getUsers() { return users; } | 无group属性 |
图表 12 数据库内生成的表
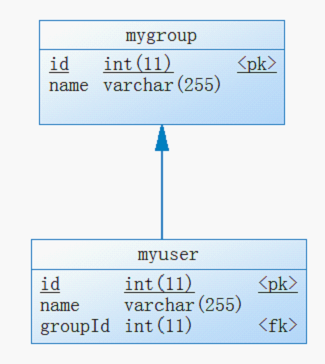
图表 13 用powerdesigner对表进行逆向的结果
1) 有JoinColumn,Group类无users属性
做出改动的代码 | |
Group类 | User类 |
无users属性 | @ManyToOne(cascade={CascadeType.ALL}) @JoinColumn(name="groupId") public Group getGroup() { return group; } |
Junit测试类改成如下 | |
package me.hibernate.model; import org.hibernate.Session; import org.hibernate.cfg.AnnotationConfiguration; import org.junit.Test; public class TestORM { @Test public void testSave(){ User u1,u2,u3; Group g; u1 = new User(); u2 = new User(); u3 = new User(); g = new Group(); u1.setName("me"); u2.setName("you"); u3.setName("him"); g.setName("bigGroup"); u1.setGroup(g); u2.setGroup(g); u3.setGroup(g); AnnotationConfiguration cfg = new AnnotationConfiguration(); Session session = cfg.configure().buildSessionFactory().getCurrentSession(); session.beginTransaction(); session.save(u1); session.save(u2); session.save(u3); session.getTransaction().commit(); } } |

图表 14 数据库内生成的表
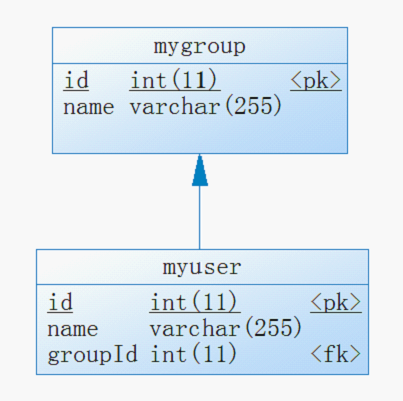
图表 15 用powerdesigner对表进行逆向的结果
1) 无JoinColumn,Group类无users属性
做出改动的代码 | |
Group类 | User类 |
无users属性 | @ManyToOne(cascade={CascadeType.ALL}) public Group getGroup() { return group; } |
Junit测试类改成如下 | |
同上 |

图表 16 数据库内生成的表

图表 17 用powerdesigner对表进行逆向的结果
一、实验结论(个人结论,谨慎采纳)
如果一对多(多对一)和多对多不是一回事的话(我认为其实他们是一回事),那么在关系数据库里只有多对多才有双向关联,一对多和多对一没有双向关联(hibernate里的一对多双向十靠hibernate自己维护的),倘若一对多和多对一有双向关联,它们已经是实际意义上的多对多关系了。
(排版不是很好,特别文章里的一些表格看起来效果好差,大家凑合看哈)